题目链接:
https://www.nowcoder.com/practice/04a5560e43e24e9db4595865dc9c63a3
解法分析:纯的层序遍历,使用 BFS
1 | /* |
题目链接:
https://www.nowcoder.com/practice/04a5560e43e24e9db4595865dc9c63a3
解法分析:纯的层序遍历,使用 BFS
1 | /* |
本文摘自字节青训营社区技术问答板块
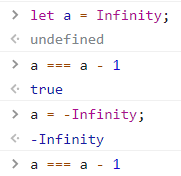
Number.MAX_SAFE_INTEGER 的数)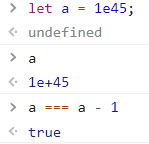
-2 ** 53 + 1 到 2 ** 53 - 1,即 -9007199254740991 到 9007199254740991。超过这个数值的整数,都不能被精确表示。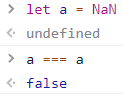
使用 defineProperty 函数
1 | let count = 0; |
1 | for (var i = 0; i < 5; i++) { |
这段代码的执行结果是什么?
答案:立刻输出一个 5,1s 后再一次性输入 5 个 5。
解释:
如果期望代码的输出变成 1s 后输出 0,1,2,3,4,该怎么改造代码?
首先思考为什么会输出 5 个 5 呢?究其缘由,var 声明的变量不存在块级作用域,所以最终的 i 都是同一个 i。也就是说,i 是声明在全局作用域中的。所以如果我们可以使 i 声明在私有作用域中,就可以解决这个 bug。
因此,我们可以利用闭包,让 i 在每次迭代的时候,都产生一个私有的作用域,在这个私有的作用域中保存当前 i 的值。
1 | for (var i = 0; i < 5; i++) { |
接着我们很自然地会想到使用 let,let 本身当然是可以的,但是此处代码的最后一行十分恶心,要求输出 i,所以会报错。
闭包解决方法的最大问题就是可读性不好。
我们可以利用一个特性:JS 中基本类型的参数传递是按值传递的。
1 | function output(i) { |
1 | for (var i = 0; i < 5; i++) { |
1 | for (var i = 0; i < 5; i++) { |
这算是一种解决方法,但是太粗暴了(x
1 | const tasks = []; // 这里存放异步操作的 Promise |
使用 await 优化其实是很简单的,实际上就相当于写同步,只要实现一个 sleep 函数就行了。(bks 异步的最终解决方案
1 | // 模拟其他语言中的 sleep 函数 |
参考资料:
https://juejin.cn/post/6844903474212143117
https://juejin.cn/post/6844903612879994887
https://juejin.cn/post/6844903841888993287
闭包是一个可以访问外部函数作用域的函数,即便外部函数已经运行完成。这意味着闭包可以记住并访问其外部函数的变量和参数,即使在函数完成之后也是如此。
在深入闭包之前,我们首先需要理解词法作用域。
Javascript 词法作用域是指我们可以获取源代码中变量、函数、对象的物理位置。
比如:
1 | let a = 'global'; |
此处函数 inner 可以获取它自己作用域、outer 函数作用域、全局作用域中的变量;outer 函数可以获取它自己作用域、全局作用域中的变量。
1 | function person() { |
在这段代码中,我们调用了 person 函数,它会返回内部的函数 displayName 并把这个内部函数存储在变量 peter 中。当我们调用函数 peter 时,实际上也就是在调用函数 displayName,因此 console 结果为 Peter。
但是在函数 displayName 里面并不存在一个叫 name 的变量,也就意味着这个函数可以以某种方式获取它外部的函数 person 中的值,甚至在 person 函数返回之后。所以 displayName 函数实际上就是一个闭包。
1 | function getCounter() { |
这次我们把一个通过 getCounter 返回的匿名函数存储在一个叫做 count 的变量中。因为 count 函数是一个闭包,它可以通过函数 getCounter 获取变量 counter 的值,即便是在 getCounter 函数已经返回之后。
这里我们需要注意的是,变量 counter 在每次调用时,并没有重置为 0。这似乎有悖我们之前对函数的认知。
这是因为每次调用函数 count 的时候,虽然都会创建一个 count 的新的函数作用域,但是对于函数 getCounter 始终只存在一个作用域,而 counter 变量是在 getCounter 的作用域中定义的,所以每次我们调用函数 count 的时候,计数会递增,而不是重置为 0。
要想清楚地理解闭包的工作原理,我们需要首先理解 Javascript 中的两个重要概念:
简单来说,执行上下文是关于 Javascript 代码解析和执行的环境的抽象概念。JavaScript 中运行任何的代码都是在执行上下文中运行的。
因为 Javascript 是单线程语言,所以一次只能有一个正在运行的执行上下文,它由一个被称为执行栈或调用栈的数据结构管理。
当前运行的执行上下文将始终位于栈顶,并且当当前函数运行完成时,对应的执行上下文会从栈顶弹出,并将控制权移交给下一个执行上下文。
请看例子: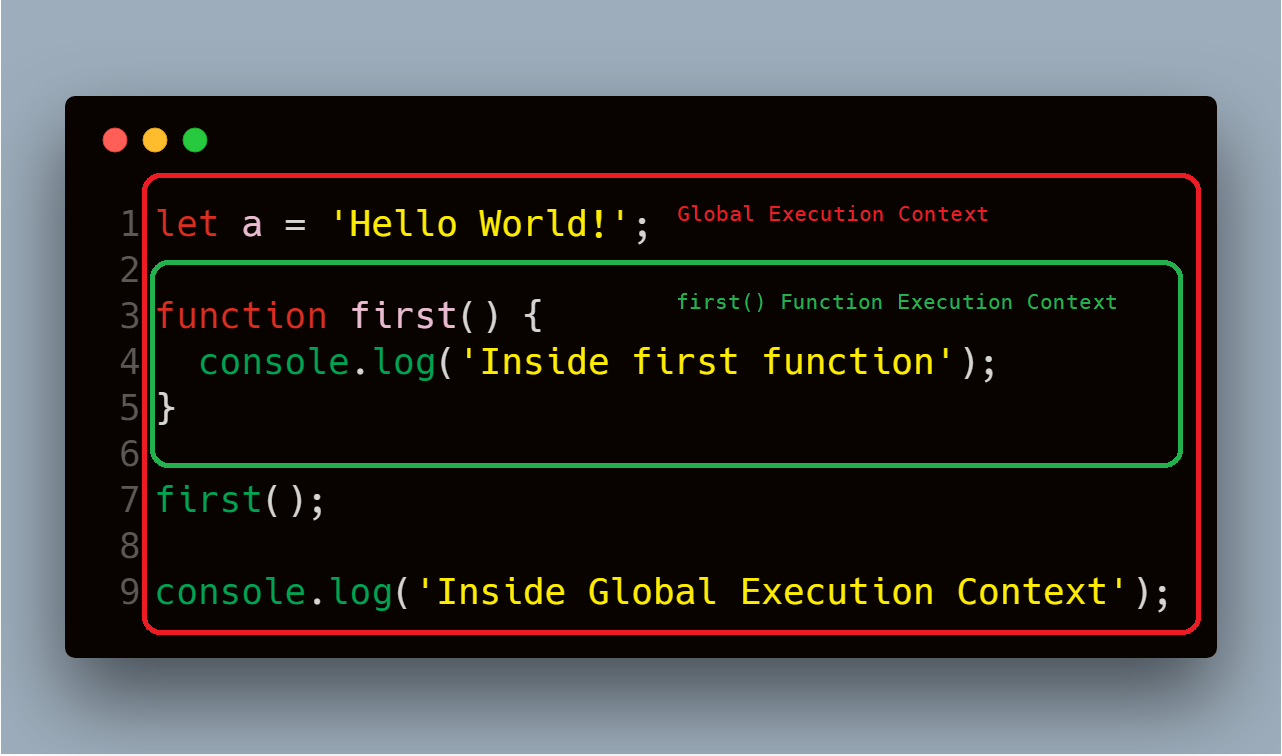
当这段代码运行时,Javascript 引擎会创建一个全局执行上下文来运行全局代码,而当遇到函数 first 时,它会为 first 函数创建一个新的执行上下文,并将其压入栈内。
执行栈的图示就像这样:
当 first 函数执行完成时,它的执行上下文会从执行栈中弹出,然后控制权移交给它下面的执行上下文,也就是全局上下文。
每当 Javascript 引擎为全局代码或者某个函数创建一个新的执行上下文的时候,它同时也会创建一个新的词法环境,用于存储函数执行过程中出现的变量。
词法环境是一个类似 (标识符, 变量) 的映射数据结构,这里的标识符具体指变量名或者函数名,而变量指的是对象的引用,包括它的函数类型或者初始值。
每一个词法环境有三个组件:
词法环境可以被抽象地表示为:
1 | lexicalEnvironment = { |
以下面这段代码为例:
1 | let a = 'Hello World!'; |
全局作用域的词法环境如下所示:
1 | globalLexicalEnvironment = { |
first 函数的词法环境如下所示:
1 | functionLexicalEnvironment = { |
函数的外部词法环境被设置为全局词法环境,因为该函数被源代码中的全局作用域包围。
注意:当函数执行完成时,它的执行上下文将从执行栈中弹出,但是它的词法环境不一定从内存中删除,这取决于该词法环境是否被它外部词法环境属性中的任意其它的词法环境所引用。
1 | function person() { |
当 person 函数执行的时候,Javascript 引擎会为这个函数创建一个新的执行上下文和词法环境。在这个函数执行完成后,它会返回 displayName 函数然后将它赋值给变量 peter。
词法环境如下所示:
1 | personLexicalEnvironment = { |
当函数 person 执行完成之后,执行上下文会从执行栈中弹出。但是它的词法环境依然在内存中,因为它的词法环境被它内部的 displayName 函数的词法环境引用了。所以它的变量在内存中依然可以获取。
简单来说就是,执行上下文删除了,但是词法环境还在。(译者注)
当 peter 函数(实际上是对 displayName 函数的引用)执行时,JavaScript 引擎为该函数创建一个新的执行上下文和词法环境。对应的词法环境如下所示:
1 | displayNameLexicalEnvironment = { |
由于 displayName 函数中没有变量,所以它的环境记录器将为空。在执行此函数期间,JavaScript 引擎将尝试在函数的词法环境中查找变量 name。
而在 displayName 函数的词法环境中没有变量 name,所以它会去外部词法环境中找,也就是还在内存中的 person 函数的词法环境。JavaScript 引擎查找到了变量 name 后,将其打印到控制台。
原文:
https://blog.bitsrc.io/a-beginners-guide-to-closures-in-javascript-97d372284dda
简单来说,执行上下文是关于 Javascript 代码解析和执行的环境的抽象概念。JavaScript 中运行任何的代码都是在执行上下文中运行的。
执行栈,也就是调用栈,它用来存储代码运行时创建的所有执行上下文。本质上它就是数据结构中所说的栈,满足先进后出。
当 JavaScript 引擎第一次读取你的脚本时,它会创建一个全局执行上下文并将其压入执行栈;每当引擎遇到一个函数调用,它会为该函数创建一个新的执行上下文并压入栈。
JavaScript 引擎会优先运行执行上下文位于栈顶的函数。当该函数运行结束时,其对应的执行上下文会从栈中弹出,上下文的控制权将被移到当前执行栈的下一个执行上下文。
示例:
1 | let a = 'Hello World!'; |

first() 函数调用时,JavaScript 引擎为该函数创建一个新的执行上下文并把它压入当前执行栈first() 函数内部调用 second() 函数时,JavaScript 引擎为 second() 函数创建了一个新的执行上下文并把它压入当前执行栈的顶部。当 second() 函数执行完毕,它的执行上下文会从当前栈弹出,并且控制权移交给下一个执行上下文,即 first() 函数的执行上下文first() 执行完毕,它的执行上下文从栈弹出,上下文控制权会被移交给全局执行上下文。一旦所有代码执行完毕,JavaScript 引擎从当前栈中移除全局执行上下文创建执行上下文有两个阶段:
在创建阶段创建执行上下文。在创建阶段会发生以下情况:
我们可以将其抽象表示为:
1 | ExecutionContext = { |
词法环境是用于保存 标识符-变量 的映射的结构。这里标识符是指变量/函数的名称,变量是对实际对象(包括函数对象和数组对象)或基本类型的引用。
简而言之,词法环境是存储变量和对象引用的地方。
根据官方的 ES6 文档,一个词法环境由环境记录器和一个可能为空的对于外部环境的引用组成。
示例:
1 | var a = 20; |
对应的词法环境为:
1 | lexicalEnvironment = { |
每一个词法环境有三个组件:
环境记录用于在词法环境中存储变量和函数声明的位置。
环境记录器有两种类型:
注意:对于函数代码,环境记录器还包含一个 arguments 对象。
示例:
1 | function foo(a, b) { |
对外部环境的引用意味着它可以访问外部的词法环境。这意味着,如果是当前词法环境中找不到的变量,JavaScript 引擎可以在外部环境中查找这些变量。
在全局执行上下文中,this 的值引用全局对象。(在浏览器中,这指的是窗口对象)
在函数执行上下文中,其值取决于函数的调用方式。如果它由对象的引用调用,则此值将设置为该对象,否则,此值将设置为全局对象或 undefined(严格模式)。
示例:
1 | const person = { |
词法环境大概如下:
1 | GlobalExectionContext = { |
它也是一个词法环境,其环境记录器保存在此执行上下文中由 VariableStatements 创建的绑定。
因为变量环境也是一个词法环境,所以它具有上面定义的词法环境的所有属性和组件。
在 ES6 中,词法环境组件和变量环境组件之间的一个区别是前者用于存储函数声明和变量(let 和 const)绑定,而后者仅用于存储变量(var)绑定。
在这个阶段,所有的变量赋值都完成了,代码最终会被执行。
示例:
1 | let a = 20; |
当上面的代码被执行时,Javascript 引擎会创建一个全局执行上下文来执行全局代码:
1 | GlobalExectionContext = { |
当函数 multiply(20, 30) 被调用时,一个新的函数执行上下文会被创建来执行函数代码:
1 | FunctionExectionContext = { |
此后,执行上下文将经历执行阶段,也就是要完成对函数内变量的赋值。(此处指对变量 g 的赋值)
1 | FunctionExectionContext = { |
函数执行完成后,返回值会被存储在变量 c 之中。所以全局的词法环境会被更新。最终,全局的代码被执行完成,程序也运行完成。
注意:你也许注意到了,let 和 const 定义的变量在创建阶段没有任何赋值操作,但是 var 定义的变量被赋值为了 undefined。这也就解释了为什么当你想获取已声明但未定义的变量时,var 声明的变量会得到 undefined,而 let 声明的变量会显示 undeclared。这也就是我们所谓的变量提升。
在本文中,我们讨论了 JavaScript 程序内部的执行机制。虽然学习这些概念并不是成为一名出色的 JavaScript 开发人员的必要条件,但对上述概念有一个良好的理解将有助于您更轻松、更深入地理解其他概念,如变量提升、作用域和闭包。
见 js 数据类型
相关知识:词法环境、调用栈
见 js 执行上下文详解(译)
相关知识:词法作用域、执行上下文、词法环境
见 js 闭包详解(译)
相关知识:词法环境
见 js 作用域和作用域链详解(译)
见 js 遍历对象
见 call、apply、bind辨析(译) & 手写实现 call、apply、bind
见 new 详解
见 js 继承
见 js 事件机制
相关知识:执行上下文、词法环境、事件循环
见 js 异步原理详解(译)
软件架构是一组用于推理系统的结构,包含了软件元素、它们之间的关系以及他们的属性
系统掩盖或修复错误的能力,使得一定时间内系统的不可用时间小于特定值
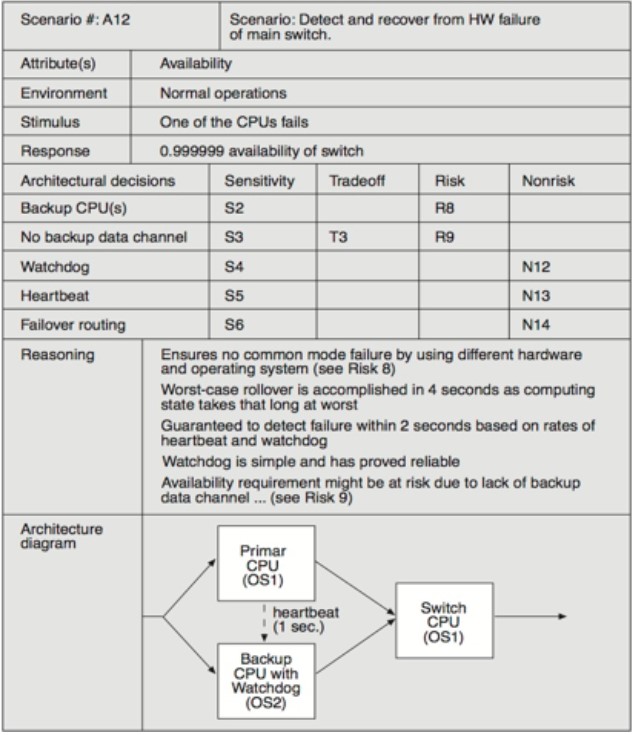
The heartbeat monitor determines that the server is nonresponsive during normal operations. The system informs the operator and continues to operate with no downtime
心跳监视器确定服务器在正常操作期间无响应。系统通知操作员继续操作,并在无停机的情况下继续运行

两个或以上的系统,在一定的背景下,可以通过接口有用地交换有意义的信息
Our vehicle information system sends our current location to the traffic monitoring system. The traffic monitoring system combines our location with other information, overlays this information on a Google Map, and broadcasts it. Our location information is correctly included with a probability of 99.9%
交通信息系统发送当前的地址信息给交通监控系统,交通监控系统需要将我们的位置信息和其他信息组合起来,映射到谷歌地图上,并发布结果。我们的位置信息被正确包含的概率将为 99.9%
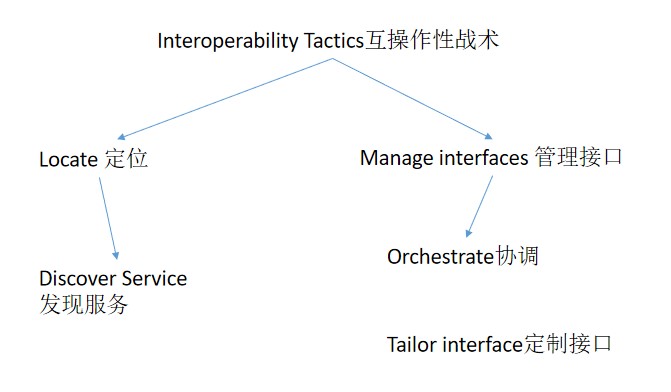
在一定时限内,软件能被无副作用修改的难易程度
The developer wishes to change the user interface by modifying the code at design time. The modifications are made with no side effects within three hours
如果开发人员在设计时希望修改代码来更改用户接口,修改可以确保在三小时内完成更改以及单元测试,而且没有副作用

软件系统满足时间需求的能力
Users initiate transactions under normal operations. The system processes the transactions with an average latency of two seconds
用户在正常操作下启动会话。系统处理事件的平均延迟为 2 秒

系统保护数据免受未授权访问和能够被授权访问的能力
A disgruntled employee from a remote location attempts to modify the pay rate table during normal operations. The system maintains an audit trail and the correct data is restored within a day
一个对工资不满的员工试图在正常操作期间远程修改工资率表。系统将保留审核跟踪,并在一天内恢复正确的数据,确定想做坏事的人是谁

软件可以被证明有错误的容易程度
The unit tester completes a code unit during development and performs a test sequence whose results are captured and that gives 85% path coverage within 3 hours of testing
单元测试人员在开发过程中完成一个代码单元,并执行一个测试序列,该序列的结果被捕获,并在测试的 3 小时内提供 85% 的路径覆盖率

指用户完成一项任务的容易程度和系统所提供用户支持的种类
The user downloads a new application and is using it productively after two minutes of experimentation
用户下载一个新的应用程序,并在两分钟的试用后就能有效地使用它
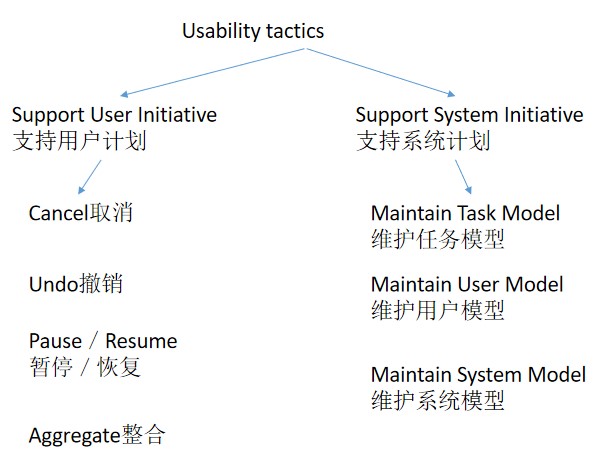
指未列出的的质量属性,如 variability 变异性、 portability 可移植性、scalability 可扩展性、elasticity 弹性、deployability 可部署性、mobility 可移动性、monitorability 可监测性等
| avalibility | testability | usability | security | performance | modifiability | |
|---|---|---|---|---|---|---|
| source | 系统内部或外部 | 单元测试人员、集成测试人员 | 用户 | 授权或非授权用户、访问了有限资源或大量资源 | 系统内部或外部 | 开发人员 |
| stimulus | 错误,如疏忽、崩溃、响应错误 | 完成了一段功能完整的代码,如类、层;完成了整个应用 | 学习系统特性、学会有效使用系统 | 尝试修改数据、尝试访问系统服务 | 定期事件到达、随机事件到达、偶然事件到达 | 增加、删除、修改功能 |
| artifact | 处理器、进程 | 代码片段、完整应用 | 系统 | 系统服务、系统数据 | 系统 | 用户界面、系统 |
| environment | 正常操作、降级操作 | 设计时、开发时、编译时、部署时 | 运行时 | 在线或离线、联网或断网 | 正常模式 、超载模式 | 设计时、构建时、编译时、运行时 |
| response | 记录故障;通知用户或系统;禁止错误的数据源 | 准备测试环境、执行测试并捕获结果 | 上下文帮助系统、撤销操作、取消操作 | 对用户进行身份验证、允许或拒绝用户访问数据或服务 | 处理事件、改变服务的级别 | 查找需要修改的位置、对内容进行修改 |
| response measure | 系统修复时间、系统可用时间间隔、系统在降级模式下的可用时间间隔 | 准备测试的时间、执行测试的时间、测试的覆盖率 | 用户学习时间、用户满意度、用户的操作成功率 | 防范成功的比例 | 等待时间、吞吐率 | 修改需要的成本、修改对其它功能的影响 |
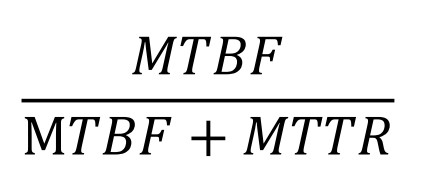
效用树是一种用于记录 ASR 的方法
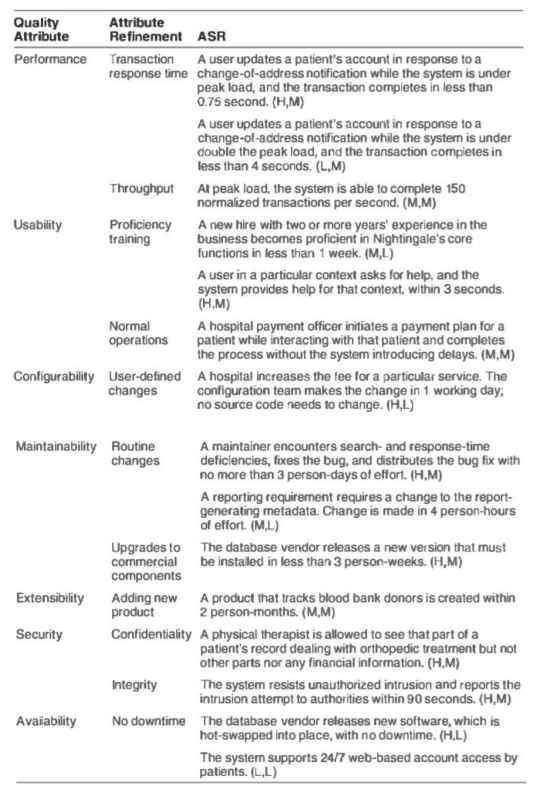
(业务价值,架构冲击) H=high, M=medium, L=low

Architecture Tradeoff Analysis Method 架构权衡评估方法
一个 ATAM 过程通常需要 20-30 天,只适用于大型昂贵的项目。所以发展出了轻量级架构评估,一般只需要一天甚至半天,只涉及组织内部的人员。这个评估方法不产生最终报告,而是由抄写员负责收集结果。只有组织内部成员来评估可能得出不客观的结果,缺乏创新和讨论。但是这个评估方法快速廉价,所以可以被快速部署,无论项目是否需要关于架构质量保证的合理性检查(sanity check)
故障是云计算中常见的情况。云提供商确保云本身将保持可用,但有一些例外
多租户带来了对非云环境的额外关注
去年对我而言是非常特殊的一年,也是从去年的暑假开始,我正式决定要走 web 前端的路。
去年主要的学习时间都放在了前端的知识点,包括 html、css、js、webpack5、node.js、react hooks 等,但是感觉好像目前还没有哪个方向研究得比较深入。前端的知识体系庞大复杂,而且涉及到的计算机基础知识也很多,让人很容易迷失学习方向。但是通过这半年来的逐渐摸索,我也大概知道了一些主流的技术栈以及学习的方向,这算是一件让人高兴的事情。不过去年最高兴的事情还是恢复了单身(
今年要开始找实习了,寒假也马上要到来了,在这画画饼做个寒假计划:
备选:
最后,新的一年,最大的愿望就是身边的人和我都能快快乐乐的!
行内:span, a, label 不独占一行,不能设置宽高
块级:div, footer, header, section, p, h1-h6 独占一行,可以设置宽高
空元素:br, hr 不独占一行,可以设置宽高
src 用于替换当前元素,href 用于在当前文档和引用资源之间确立联系
<link href="common.css" rel="stylesheet"/> 那么浏览器会识别该文档为 CSS 文件,然后并行下载资源并且不会停止对当前文档的处理。这也是为什么建议使用 link 方式来加载 CSS,而不是 @import 方式