Function.prototype.myBind = function (context, ...args) { if (typeof (this) !== 'function') { thrownewTypeError('The bound object needs to be a function'); } const _this = this;
returnfunctionnewFunction() { // 使用了 new if (thisinstanceof newFunction) { returnnew _this(...args); } else { return _this.call(context, ...args); } } }
let a = { name: 'poetries', age: 12 } functionfoo(a, b) { console.log(this.name); console.log(this.age); console.log(a); console.log(b); } foo.myBind(a, 1, 2)(); // => 'poetries'
const john = { name: 'John', age: 24, }; const jane = { name: 'Jane', age: 22, };
functiongreeting() { console.log(`Hi, I am ${this.name} and I am ${this.age} years old`); }
我们可以使用 bind 方法来让 this 指向 john 和 jane 对象。
1 2 3 4 5 6
const greetingJohn = greeting.bind(john); // Hi, I am John and I am 24 years old greetingJohn(); const greetingJane = greeting.bind(jane); // Hi, I am Jane and I am 22 years old greetingJane();
此处 greeting.bind(john) 创建了一个新的函数,且 this 指向了传入的 john 对象,接着把它赋值给了变量 greetingJohn
functiongreeting() { console.log(`Hi, I am ${this.name} and I am ${this.age} years old`); } const john = { name: 'John', age: 24, }; const jane = { name: 'Jane', age: 22, }; // Hi, I am John and I am 24 years old greeting.call(john); // Hi, I am Jane and I am 22 years old greeting.call(jane);
上面例子我们可以看出 call 的结果是立即执行该函数。
call 接收多个参数
call 可以接收多个参数。
例如:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
functiongreet(greeting) { console.log(`${greeting}, I am ${this.name} and I am ${this.age} years old`); } const john = { name: 'John', age: 24, }; const jane = { name: 'Jane', age: 22, }; // Hi, I am John and I am 24 years old greet.call(john, 'Hi'); // Hello, I am Jane and I am 22 years old greet.call(jane, 'Hello');
functiongreet(greeting, lang) { console.log(lang); console.log(`${greeting}, I am ${this.name} and I am ${this.age} years old`); } const john = { name: 'John', age: 24, }; const jane = { name: 'Jane', age: 22, }; // Hi, I am John and I am 24 years old greet.apply(john, ['Hi', 'en']); // Hello, I am Jane and I am 22 years old greet.apply(jane, ['Hello', 'es']);
var greeting = 'Hello World!'; functiongreet() { console.log(greeting); } // Prints 'Hello World!' greet();
函数作用域
函数中声明的变量在函数作用域内,这些变量只能从该函数的内部访问,不能从外部区域访问。例如:
1 2 3 4 5 6 7 8
functiongreet() { var greeting = 'Hello World!'; console.log(greeting); } // Prints 'Hello World!' greet(); // Uncaught ReferenceError: greeting is not defined console.log(greeting);
块级作用域
对于 ES6 的 let 和 const 关键字声明的变量,不像 var 声明的变量,它们可以通过最近的一对花括号形成块级作用域。也就是说,在花括号外部不能访问花括号里面声明的变量。例如:
1 2 3 4 5 6 7 8 9
{ let greeting = 'Hello World!'; var lang = 'English'; console.log(greeting); // Prints 'Hello World!' } // Prints 'English' console.log(lang); // Uncaught ReferenceError: greeting is not defined console.log(greeting);
作用域的嵌套
就像 JavaScript 的函数一样,一个作用域可以被另一个作用域包裹。例如:
1 2 3 4 5 6 7 8 9
var name = 'Peter'; functiongreet() { var greeting = 'Hello'; { let lang = 'English'; console.log(`${lang}: ${greeting}${name}`); } } greet();
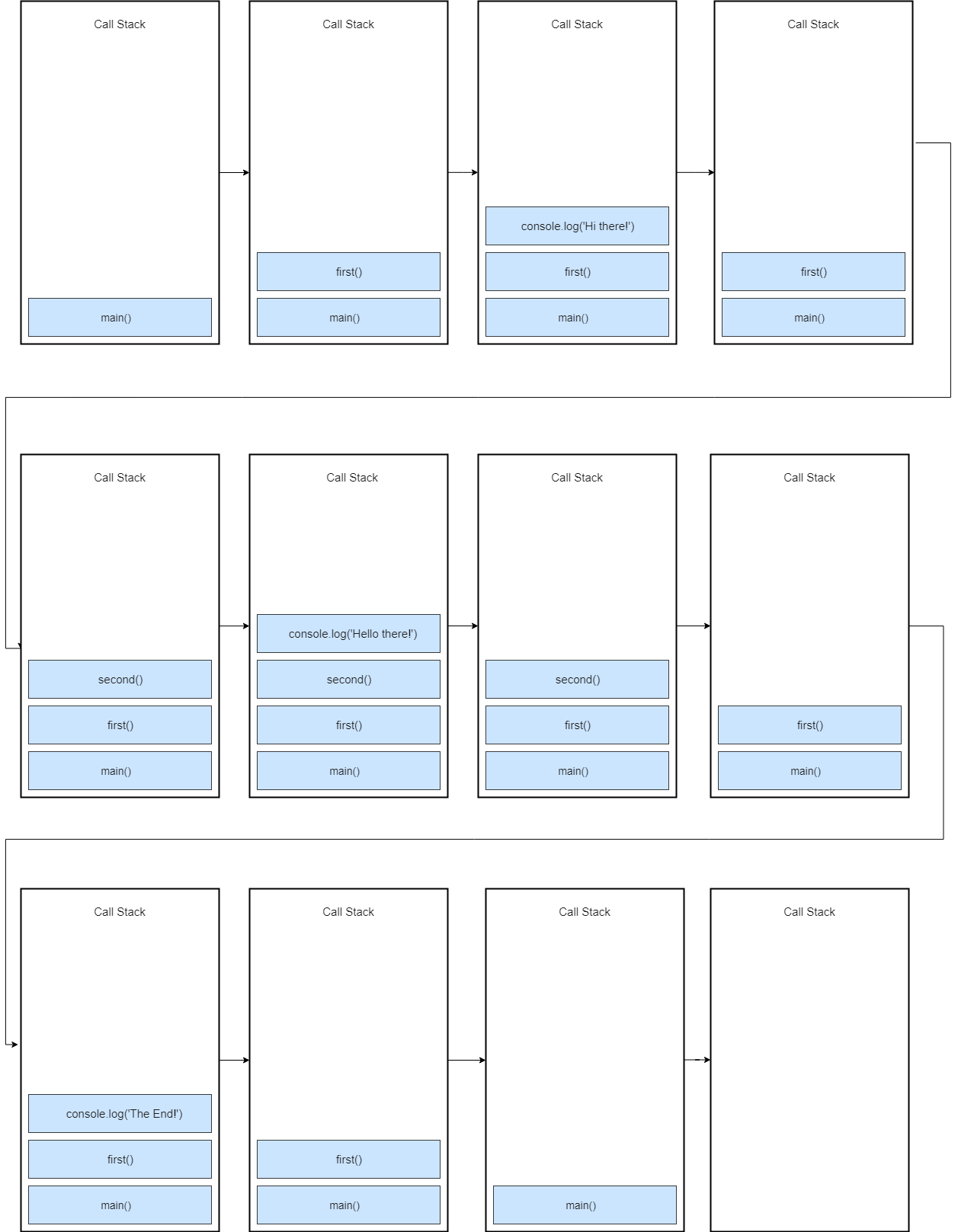
let foo = 'foo'; functionbar() { let baz = 'baz'; // Prints 'baz' console.log(baz); // Prints 'foo' console.log(foo); number = 42; console.log(number); // Prints 42 } bar(); console.log(number); // 42
当函数 bar 被执行时,JavaScript 引擎会去寻找变量 baz,然后在当前作用域找到了。接着,它会去寻找变量 foo,然后发现无法在当前作用域中找到。所以它会去外部的作用域中寻找,然后成功找到了该变量。 之后,JavaScript 会在当前作用域和外部作用域中寻找 number 变量,但是发现找不到。此时如果是非严格模式,会在全局声明一个变量 number 并给它赋值 42;若是在严格模式下,将会报错。 总而言之,当一个变量被使用的时候,JavaScript 引擎会沿着作用域链去遍历这个变量直到找到或到达全局作用域。
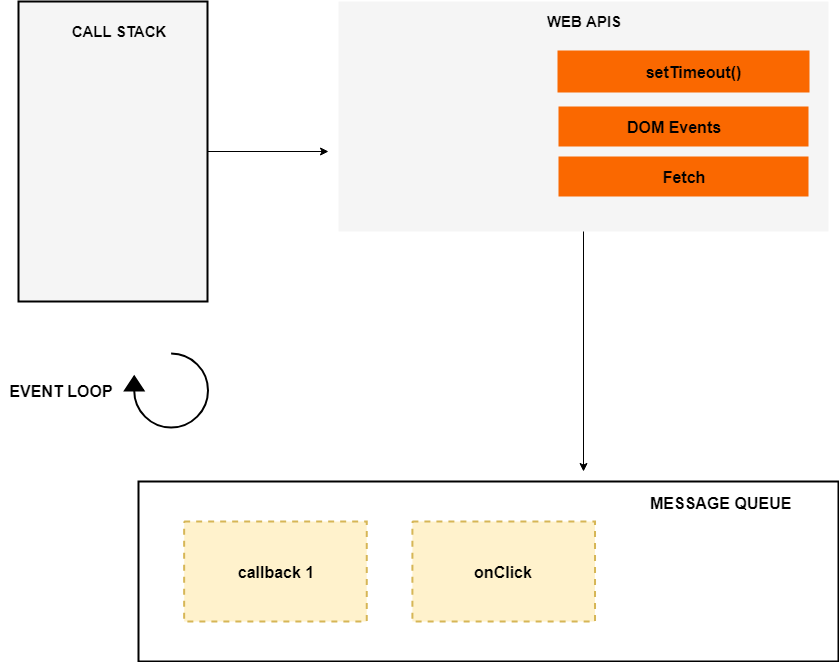
这里我用 setTimeout 函数来模拟网络请求。请牢记 setTimeout 不是 Javascript 引擎的一部分,而是 web API 的一部分。(在 Nodejs 中,web API 被 C/C++ API 所取代) 为了理解这段代码是如何执行的,我们需要了解更多的相关概念,比如事件循环和任务队列(也叫消息队列)。
JavaScript 运行时环境的概述
事件循环、web API 和任务队列不是 JavaScript 引擎的一部分,而是浏览器 JavaScript 运行时环境或 Nodejs 的 JavaScript 运行时环境的一部分。(在 Nodejs 中,web API 被 C/C++ API 所取代)